TCP 流量控制:滑动窗口、流量控制、拥塞控制 (下)
3.1 为什么需要流量控制?
想象一下这样一个场景:一个超级快的外卖配送员不断地往你家送外卖,但你的冰箱空间有限,根本放不下这么多食物。
这就是网络通信中的一个常见问题:发送方发送数据的速度可能比接收方处理数据的速度快得多。
如果不加以控制,就会导致数据丢失、网络拥塞等问题,这就是为什么我们需要TCP流量控制。
所以流量控制的目的就是让发送方发送速度和接收方相匹配。
3.2 TCP 流量控制是如何实现的?
利用我们前面讲到的滑动窗口机制,接收方通过调整接收方窗口大小,可以很方便实现对发送方发送速率的控制。
接下来还是画一张图来展示一下这个过程:

在上面图片中这个案例,发送方初始时拥有一个400字节的可用窗口,这个窗口代表了在不等待对方确认的情况下,发送方可以连续发送的数据量。
就像是一个在传送带上滑动的窗口,窗口内的数据可以被发送,随着 ACK 的到来,窗口会向前滑动。
数据传输过程
第一阶段:正常传输:
发送方首先发送1-100字节的数据,接着发送101-200字节,然后发送201-300字节,最后发送301-400字节。
发送方每次发送完数据后,窗口就会相应地向前移动,直到全部可用窗口用完,不能再继续发送数据,必须等待接收方确认。
第二阶段:丢包处理:
在发送301-400字节的数据包时发生了丢包。这时系统的处理过程如下:
接收方发现收到了乱序数据,发送ACK=301,表示期望收到301字节开始的数据,接收方同时将窗口调整为200字节,这是进行流量控制。
发送方收到ACK=301后,知道前300字节已经被确认,发送窗口向右移动 300 字节,此时还有 301-400 未被确认,并且窗口被调整为 200 字节,所以还可以继续发送 401-500 字节的数据。
第三阶段: 超时重传:
当发送方重传计时器超时后发现301-400字节的数据包可能丢失:
- 触发超时重传,重新发送301-400字节的数据
- 接收方成功收到重传的数据和之前的401-500字节数据,发送ACK=501,并将接收窗口调整为100字节,进行流量控制
- 发送方收到 ACK 501 后,知道前面 500 字节数据已经被确认,发送窗口向右移动 200 字节,但由于此时窗口大小已经被调整为 100 字节,所以只能继续发送501-600字节的数据。
第四阶段:暂停发送:
最后接收方收到 501-600 的数据,回复一个 ACK 601,同时将接收方窗口调整为 0,此时:
- 接收方通过ACK=601确认所有数据
- 窗口调整为 0,迫使发送方暂停发送,直到接收方重新分配窗口空间
整个过程为了方便理解,我们只画了 Client 到 Server 的数据发送和 Server 对 Client 进行的流量控制,但实际上 TCP 是全双工协议,数据发送是双向的,Client 也会对 Server 进行流量控制,道理都是一样的。
这个例子中,接收方可能由于缓冲区满,应用层来不及接收,在不断的减缓接收方窗口,以此降低发送方发送速率,并在最后将接收窗口调整为 0,这将暂停发送方的数据发送。
窗口减小到 0,我们称之为窗口关闭
3.3 TCP 零窗口处理
上面这个例子中,我们看到接收方通告发送方窗口为 0,那是不是说发送方就没法再发送数据了呢?
其实不是,当接收方缓冲区又空出来之后,它就会重新发送一个非零窗口通知报文(实际是 ACK 上携带 窗口大小),如下图:

当接收方收到后,又会重新更新窗口大小,重新启动发送数据。
这里可能有同学会产生疑问了,万一接收方的非零通知报文 丢了怎么办?
那 Client 就会一直等待 Server 的的通知报文,而 Server 也认为自己已经通知了,一直等待 Client 发送来的数据。
如果不采取其它措施,双方将陷入死锁状态:

零窗口探测报文
那么如何解决这种潜在的死锁问题呢?
在 TCP 连接中,当发送方发现接收窗口的大小为 0,且长时间未收到接收方窗口大小更新的消息时,它会启动 持续计时器,并定期发送 零窗口探测报文(Zero Window Probe)。
这些探测报文一般只包含非常少的数据(如 1 字节),用于探测接收方的接收窗口是否已经恢复。
如下图所示:

- 当发送方收到零窗口通知时,启动了持续计时器
- 当持续计时器超时,发送方发送了零窗口探测报文
- 对于零窗口探测报文,即便接收方接收窗口为 0,也需要发送应答数据包,回复当前自己的窗口
如果发送方的零窗口探测报文丢失了怎么办呢?
这个探测报文段本身是有超时计时器的,所以会被重传。
如果发送方收到的还是零窗口怎么办呢?
发送方还会继续启动持续计时器,持续的发送零窗口探测报文,探测的间隔时间一般初始是几秒钟,通常会采用指数退避算法逐渐增长到几十秒。
其实我还有一个疑问:
第一个窗口非零通知报文丢失了,为什么 Server 不重传?
在 rfc6429 ,我找到了答案:
It is extremely important to remember that ACK (acknowledgment)
segments that contain no data are not reliably transmitted by
TCP.
这段话的意思是TCP 无法可靠传输不包含数据的 ACK 报文
也就是说不会为这种不携带数据的窗口通知报文提供重传,原因也很好理解,因为没携带数据,那么接收方收到也不会回应 ACK(否则就套娃了),所以你也没法判断对方到底收到没,也就没法应用重传机制。
这个结论很重要:
不携带数据的 ACK 报文不会被重传
3.4 TCP 糊涂窗口综合征(Silly Window Syndrome)
TCP糊涂窗口综合症是指 TCP 数据传输过程中,出现大量小数据包传输的现象。
这就像是邮局配送包裹时,不断地派出快递员送非常小的包裹,而不是等待将多个包裹合并后一次性配送,这样显然会造成资源的浪费。
为什么叫"糊涂"?
之所以称为"糊涂",是因为这种传输方式看起来非常不明智:
- 每个TCP包都包含至少 40 字节的头部信息
- 如果数据部分太小(比如只有 1-2 字节),就会造成很大的传输开销
- 这种行为就像"糊涂"了一样,明明可以更高效等数据多了一起发送,却选择了最笨拙的方式
造成这种糊涂的可能是发送方有数据就发送,等待累积数据,也可能是接收方频繁向发送方通知小窗口。
下面我们分别图解一下这两种情况:
1. 接收方处理速度太慢导致糊涂窗口
我们假设接收方缓冲区固定 400 字节,而接收方应用程序处理速度较慢:

这张图展示了 TCP 糊涂窗口综合症的形成过程,简单解释下:
- 初始状态
- 接收方有 400 字节的接收缓冲区
- 发送方开始分批发送数据
- 数据传输开始
- 发送方首先发送 1-100 字节,接着发送 101-200字节
- 接收方收到数据并存入缓冲区
- 问题开始显现
- 接收方应用程序处理速度很慢,只处理了50字节,由于缓冲区累积了未处理的数据,可用空间减少
- 接收方通告窗口从400字节减小到250字节(400-200 + 50)
- 问题逐渐恶化
- 发送方发送更多数据,而应用程序继续慢速处理
- 接收方的可用窗口逐渐减小:250字节 → 50字节 → 30字节
- 最终形成了"糊涂窗口":接收方通告非常小的窗口,导致发送方只能发送小量数据
出现这种问题在于:
- 发送方被迫发送小包数据
- 每个小包都有 TCP 头部开销,网络传输效率严重降低(比如网络传输 50 字节数据有 40 字节是头部)
这就是典型的由接收方处理速度慢导致的 TCP 糊涂窗口综合症。
2. 发送方导致糊涂窗口综合症
如果应用程序频繁写入小量数据(10字节、5字节、2字节),比如 telnet。
而 TCP 又立即发送这些小数据包,没有等待或合并多个小数据包,就会导致网络中很多小数据包。
每个小数据包都需要 40 字节的TCP头部,网络带宽利用率极低,这种就像本来可以坐 200人的飞机里只做了一两个人就起飞。
画个图来表达:

所以糊涂综合症的根本原因在于:
- 接收方过早通告小窗口
- 发送方没有等待数据聚集一起发,而是不断发小数据包
那么如何解决呢?
针对接收方和发送方有两种不同的方式:
Clark 解决方案(接收方)
Clark 解决方法是只要有数据到达就发送确认,但是如果窗口大小小于 【缓存空间一半】或者小于 【MSS】 就发送 0 窗口通知,反之才发送实际的空闲窗口大小。
用代码来表达:
def clark_window_advertisement(buffer_size, free_space, mss):
"""
Clark算法实现窗口大小通告
参数:
buffer_size: 接收缓存的总大小
free_space: 当前可用的空闲空间
mss: 最大报文段大小
返回值:
advertised_window: 向发送方通告的窗口大小
"""
# 计算阈值:缓存大小的一半或MSS中的较小值
threshold = min(buffer_size // 2, mss)
# 如果空闲空间小于阈值,通告0窗口
if free_space < threshold:
advertised_window = 0
else:
# 否则通告实际的空闲空间大小
advertised_window = free_space
return advertised_window很多同学可能会想,如果明明有空闲窗口,但是发送0,会不会减慢 TCP 传输速度?
实际上并非如此,因为这种情况下,整个数据传输的瓶颈在于接收端应用层过载,导致接收端缓冲区的消耗速率远小于发送速率,那么我们可以让发送端适当的休息,把很多小的数据包合并为大的数据包。
还有一个方法,就是 TCP 延迟确认技术:
接收方不会在报文段到达时立即确认。而是等待直到接收缓存中有足够的空间,才发送确认。这种机制阻止了发送方滑动窗口,导致发送方在发送完数据后就会暂停发送。
缺点: 延迟确认可能导致发送方误认为报文段丢失而触发重传,因为发送方无法及时收到确认。
平衡机制: 为了在效率和可靠性之间取得平衡,协议规定了延迟确认的最大时间不能超过500毫秒。这样既保留了延迟确认的优势,又避免了过度延迟带来的问题。
Nagle 算法(发送方)
Nagle算法是为了解决发送方导致的糊涂窗口综合症而设计的,当时John Nagle 观察到很多应用程序会频繁发送小数据包,严重影响网络效率。
RFC 将 Nagle 算法定义为:
inhibit the sending of new TCP segments when new outgoing data arrives from the user if any previously transmitted data on the connection remains unacknowledged.
意思是如果连接上任何先前传输的数据仍未得到确认,则当用户有新的传出数据到达时,禁止发送新的 TCP 段。
实际上,Nagle算法的基本规则很简单,总结下来两点:
- 在任意时刻,最多只能有一个未被确认的小段(< MSS),剩下的小段需要等待之前的数据被确认后才能发送
- 如果积累的数据达到了 MSS,则可以立即发送
注意,注意,注意!!!这里关于【为被确认的小段】很多博主写的都有误!
不是指最多只能有一个未确认数据包,而是一个未确认的小段!小段的意思是小于 MSS,所以Nagle算法实际上是在说:
- 如果你要发小包,一次只能发一个,必须收到 ACK 再发
- 如果你发的是 MSS 大小的包,可以一直发
维基百科上也有伪代码:
if there is new data to send then
if the window size ≥ MSS and available data is ≥ MSS then
send complete MSS segment now
else
if there is unconfirmed data still in the pipe then
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if翻译一下:
如果有新的数据需要发送,则
如果窗口大小 ≥ MSS 且可用数据 ≥ MSS,则
立即发送完整的 MSS 数据段
否则
如果仍有未确认的数据,则
将数据放入缓冲区,直到收到确认
否则
立即发送数据用代码表达一下:
def nagle_send(data_size, mss, has_unacked_small_segment):
"""
Nagle算法的核心决策逻辑
参数:
data_size: 要发送的数据大小
mss: 最大报文段大小
has_unacked_small_segment: 是否有未确认的小段
返回值:
bool: 是否立即发送数据
"""
# 如果数据大小达到MSS,立即发送
if data_size >= mss:
return True
# 如果没有未确认的小段,立即发送
if not has_unacked_small_segment:
return True
# 否则缓存起来,等待积累或ACK
return FalseNagle 算法也有缺点:
- 可能增加延迟(实时游戏等)
- 对交互式应用(ssh、telnet等)有影响
对于 实时应用,禁用 Nagle 算法是一个常见的优化手段,以确保低延迟。通过 Socket 参数 TCP_NODELAY 可以关闭 Nagle算法:
int flag = 1;
setsockopt(socket_fd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));Nagle 算法和延迟ACK的相互影响
Nagle 算法目的是合并小的 TCP 包为一个,避免过多的小报文浪费带宽
而 TCP 延迟确认 也是出于类似的目的,用于减少 ACK 包 的数量。通常,接收方不会对每个数据包立即发送一个 ACK,而是会等 200 毫秒 或者更长时间,看是否会接收到更多的数据包,然后一起发送一个确认包。这样可以减少确认包的数量,提高网络效率。
如果 TCP 连接的发送方启用了 Nagle,而另一端启用了延迟确认,且连续发送多个小的数据包: write-write-read 则可能会出现这样的情况:

如图所示:
- 发送方发送第一个小包,接收方收到后,不是完整的数据,没法处理,继续等待read,则 TCP 协议栈会延迟200ms 再确认 ACK
- 发送方虽然有更多数据要发送,但因为 Nagle 算法要等待 ACK
- 直到接收方的延迟确认到达,发送方才能发送下一个包
这种交互导致了额外的延迟,每个小包都可能遇到约 200ms 的等待时间。
维基百科百科上说上面 write-write-read 这种模式会触发这种问题,而 write-read-write-read 则不会,为什么呢?
如图所示:

原因在于 write-read-write-read 场景:
- 第一个 write 发送的是完整的数据
- server read 操作会接收到完整的数据,处理完后,立即发送回包,回包会携带ACK
- 所以第二个 write 不会被阻塞
- 整个过程没有延迟等待,每一个 write 前都能正常收到上一个数据包的 ack
所以建议,应用层把多个小包 write-write-read,合并为一个 write-read 发送。
四、TCP 拥塞控制(congestion control)
4.1 为什么需要拥塞控制?
我们知道,在真实的网络是有传输瓶颈的,因为网络传输过程中会经过网线、路由器等设备,网线具有带宽限制,路由器等中转设备有缓存限制,一旦网络中传输的数据超过其承载能力,就会导致:
- 路由器缓冲区溢出,丢弃数据包
- 传输延迟增加
- 网络吞吐量下降
- 重传次数增加,进一步加重网络负担
最后会导致大家都没法传输数据,所以我们需要拥塞控制:

在这张图中(来源湖大教书匠课程),理想的传输曲线是达到整个网络最大吞吐量后持平(绿线),然后如果没有拥塞控制,最后的现象就是大家都疯狂发,然后疯狂丢包,最后吞吐量反而恶化(红线),在有了拥塞控制之后,勉强能做到蓝色曲线的水平。
这让我想起上次早上开车去上班经历的堵死案例,这就是在没有交警约束,红绿灯短暂混乱后,左转、掉头、直行等各个方向的车都想先走,最后是成为一个螺旋状堵死,大家都走不了:

没有合适的拥塞控制机制,就容易出现网络拥塞的情况,就像在没有红绿灯和限速的高速公路上,车辆可能会堵塞一样。
但是注意,由于底层的 IP 层数据包不会对发送方做任何网络拥塞程度的反馈,所以拥塞控制是完全依靠 TCP 在两端系统上实现的软件算法。
可以理解为,给每一个人植入了拥塞控制算法,大家都能做到文明礼让,不争不抢,而不是在路中间增加交警、红绿灯(硬件改造)。
4.2 TCP 拥塞控制和流量控制有什么区别?
流量控制的目的是为了让发送方速率和接收方匹配,而拥塞控制是从整个网络全局出发,检测拥塞是否发生,如果发生则自发调整发送速度,以恢复网络。
流量控制确保接收方不会过载,拥塞控制避免整个网络过载。
都是通过控制发送方窗口来实现的。
用一张图它们之间的异同如下:

4.3 拥塞控制核心概念
TCP 拥塞控制主要通过以下两个关键参数来实现:
拥塞窗口(Congestion Window,cwnd):发送方维护的一个状态变量,用于限制可以发送但未收到确认的数据量
慢启动门限(Slow Start Threshold,ssthresh):用于决定是使用慢启动算法还是拥塞避免算法
当 cwnd <= ssthresh 使用慢启动算法 (cwnd= ssthresh 用哪个, 实际上看 Linux 代码看出来的,后面会提到)
当 cwnd > ssthresh 使用拥塞避免算法
之前我们讲到了 发送方窗口和接收方窗口 rwnd 有关,发送方窗口会逐步靠近 rwnd,但是引入拥塞窗口之后,实际的发送窗口由这两者共同决定:
实际发送窗口 = min(拥塞窗口cwnd, 接收窗口rwnd)
但是为了聚焦谈论拥塞控制算法和简化计算,在这一节中,我们默认:
- 接收窗口足够大,因此发送窗口仅由拥塞窗口决定。
- 以最大报文段 MSS 的个数为讨论问题的单位,而不是以字节为单位(MSS 可以换算到字节的)。
什么叫拥塞?TCP 怎么感知拥塞?
有两个方式:
- 没有按时收到应该收到的 ACK 报文,也就是发送方发生了超时重传事件
- 收到来自接收方的 3 个冗余ACK(冗余是指,原本还有一个,再加三个重复的,总共四个相同的 ACK)。
在本节我们总共会介绍四个基本的算法(课本介绍的早期算法):
- 慢启动
- 拥塞避免
- 快重传
- 快恢复
另外,也会补充一些最新改进的算法,比如 TCP New Reno、TCP BIC 和 TCP CUBIC 等。
4.4 拥塞控制基础算法
1. 慢启动(Slow Start)
尽管名字中包含"慢"字,但这个阶段实际上是指数增长的,慢主要体现在开始时间拥塞窗口 cwnd 较小, 一开始向网络注入的报文段少,整个慢启动过程如下:
- 连接建立时,cwnd 初始化为 1 个MSS(最大报文段大小)
- 每收到一个 ACK 确认,cwnd 增加 1 个MSS
- 每经过一个RTT(往返时延),cwnd 翻倍
- 当 cwnd 达到 ssthresh值时,进入拥塞避免阶段
这里面我发现很多同学包括我初学的时候都有一个疑问:
为什么说每经过一个 RTT,cwnd 就翻倍呢?当发送方发送了多个 MSS 报文的时候,接收方不是可以累积确认吗?那多个 MSS 报文就被合并为 一个 ACK 确认,那这里一轮结束就只能增加一个 MSS。
这就是抽象的理想情况和实际写代码差异的地方,实际场景中,也不是按照一个 ACK 报文,增长一个 MSS,而是 By 字节为单位,那么不管这个 ACK 合并还是不合并就不影响代码处理了。
当然,实际上也不太可能是完全根据轮次指数增长,因为多个数据包不同时间发出去,必然大于一个 RTT。
我们来看下实际 Linux 内核慢启动计算的代码就明白这个逻辑了:
内核版本 5.0,代码路径: net/ipv4/tcp_cong.c
在线阅读链接: https://elixir.bootlin.com/linux/v5.0/source/net/ipv4/tcp_cong.c#L393
/* Slow start is used when congestion window is no greater than the slow start
* threshold. We base on RFC2581 and also handle stretch ACKs properly.
* We do not implement RFC3465 Appropriate Byte Counting (ABC) per se but
* something better;) a packet is only considered (s)acked in its entirety to
* defend the ACK attacks described in the RFC. Slow start processes a stretch
* ACK of degree N as if N acks of degree 1 are received back to back except
* ABC caps N to 2. Slow start exits when cwnd grows over ssthresh and
* returns the leftover acks to adjust cwnd in congestion avoidance mode.
*/
u32 tcp_slow_start(struct tcp_sock *tp, u32 acked)
{
// acked 的含义: /* Number of packets newly acked */
// 更新拥塞窗口 = (当前窗口 + 新的已确认字节数) 和 ssthresh 小的那一个
u32 cwnd = min(tp->snd_cwnd + acked, tp->snd_ssthresh);
// acked = acked - (cwnd - tp->snd_cwnd)
// 返回新的 acked = 原acked 值 - 窗口增长值
// 这里的目的是如果新的已确认 acked 字节数没有全部用于增加窗口,就被 ssthresh 限制了
// 那么需要计算还剩下多少被确认的数据可以用来增加拥塞避免增窗计数器
acked -= cwnd - tp->snd_cwnd;
// 窗口值不能超过最大 snd_cwnd_clamp
tp->snd_cwnd = min(cwnd, tp->snd_cwnd_clamp);
return acked;
}再来看下哪里调用的慢启动函数:
https://elixir.bootlin.com/linux/v5.0/source/net/ipv4/tcp_cong.c#L433
在 TCP Reno 版本的拥塞避免函数内部:
/*
* TCP Reno congestion control
* This is special case used for fallback as well.
*/
/* This is Jacobson's slow start and congestion avoidance.
* SIGCOMM '88, p. 328.
*/
void tcp_reno_cong_avoid(struct sock *sk, u32 ack, u32 acked)
{
struct tcp_sock *tp = tcp_sk(sk);
if (!tcp_is_cwnd_limited(sk))
return;
/* In "safe" area, increase. */
// 如果在慢启动区间,则执行慢启动算法
if (tcp_in_slow_start(tp)) {
// 计算慢启动算法,并且拿到最新的返回值 acked
acked = tcp_slow_start(tp, acked);
// 如果 acked 等于 0,那么 !acked 为 true,也就是当前新确认的acked 字节数全部用于窗口值增加了
// 所以还在慢启动范围,不需要进入拥塞避免阶段,所以直接 return
// 如果 acked > 0,说明慢启动结束
if (!acked)
return;
}
// 如果不在慢启动范围,或者慢启动已经超过了 ssthresh (acked非 0),那么就进入拥塞避免的窗口计算 tcp_cong_avoid_ai
// 我们后面再来看这个函数的不同版本实现!
/* In dangerous area, increase slowly. */
tcp_cong_avoid_ai(tp, tp->snd_cwnd, acked);
}看到这大家应该就明白了,实际计算不管是接收方累积确认 ACK 还是一个个确认 ACK,acked 都是新确认的字节数,都不影响,也就是 ack 是按字节数来的,而不是收到的 ack 包,但是我们讨论问题用 ack 包更加的简便。
接下来看个实际案例吧:
如图所示:
- 初始 cwnd = 1,第一次发送 1 个 MSS 包
- 第 1 个RTT后,收到 1 个 ACK,cwnd 增加 1,cwnd = 2
- 在 2 个 RTT 开始,同时发送 2 个MSS 包
- 在 2 个 RTT 结束后,收到 2 个 ACK,cwnd 增加 2,cwnd = 4
- 以此类推,第三个 RTT 结束后,cwnd = 8
- ...
在这种理想讨论下,我们认为 cwnd 个 MSS 包是近似一起发出去,然后在一个 RTT 内同时收到 cwnd 个 ACK 包,所以说慢启动阶段一个 RTT 之后 cwnd 翻倍,cwnd 和传输轮次(RTT)的折线图如下所示:

虽然称为“慢启动”,但实际上比拥塞控制阶段的窗口增加更为激进。
这种指数级别的增长速率是很恐怖的,要不了几个轮回,发送速度就会爆表,所以不能一直这么“慢启动”下去,那么什么时候结束慢启动呢?
一般两种情况会终止慢启动过程:
- 出现数据包丢失,则 TCP 推断网络出现了拥塞,会缩小拥塞窗口 cwnd 来降低网络负载,这些是靠具体使用的 TCP 拥塞算法来进行计算的。
- 达到慢启动阈值(ssthresh),慢启动算法就会转换为线性增长的阶段,即 拥塞避免
这里提一下 Linux 中初始窗口 init_cwnd 取值的演进,可以通过当前 sysctl net.ipv4.tcp_init_cwnd 命令查看,现在大多是 10 (内核版本>=3.0), 表示 10 个 MSS。
我们可以通过看源代码(tcp 很多默认参数定义在 include/net/tcp.h)看演进的历程,当前可以看出是根据 rfc6928 确定的:
/* TCP initial congestion window as per rfc6928 */
#define TCP_INIT_CWND 10https://github.com/torvalds/linux/blob/master/include/net/tcp.h#L243
我们通过 Git Blame 可以看到这个参数是在哪个 commit 被更新的:
https://github.com/torvalds/linux/commit/442b9635c569fef038d5367a7acd906db4677ae1
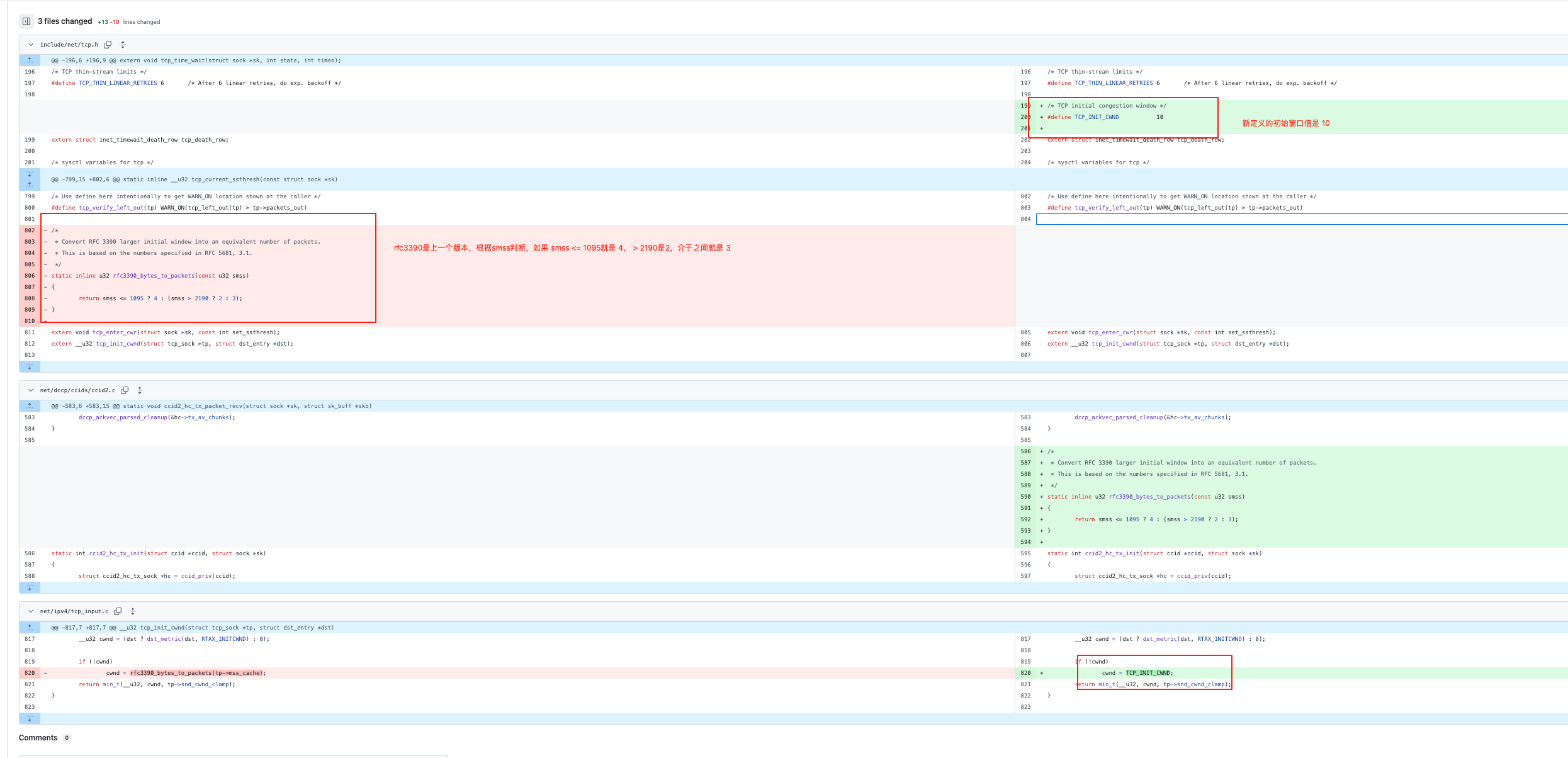
可以看到在 Linux 3.0之前,内核采用的是 RFC 3390和 RFC5681建议,根据 MSS 来确定:
- MSS <= 1095 是 4
- MSS > 2190 是 2
- 1095 < MSS <= 2190 是 3
/*
* Convert RFC 3390 larger initial window into an equivalent number of packets.
* This is based on the numbers specified in RFC 5681, 3.1.
*/
static inline u32 rfc3390_bytes_to_packets(const u32 smss)
{
return smss <= 1095 ? 4 : (smss > 2190 ? 2 : 3);
}也挺合理的,就是 MSS 越大,cwnd 越小,最后乘起来的字节数相差不大。
Linux 3.0 之后默认是 10,这也是来自谷歌的论文 An Argument for Increasing TCP’s Initial Congestion Window,后面也进入了 RFC 6982
2. 拥塞避免(Congestion Avoidance)
cwnd 不可能一直按照指数级别增长,当 cwnd 超过 ssthresh 后,就进入了拥塞避免阶段:
- 每收到一个 ACK 确认,cwnd增加 1/cwnd 个
- 相当于每经过一个RTT,cwnd 线性增加 1 个MSS
增长速度如图所示,这个阶段 cwnd 增长速度明显慢于慢启动阶段,增长由指数变为了线性,这就像司机在较为拥挤的道路上谨慎驾驶,缓慢提速。:

那么拥塞避免的 cwnd 计算方式在 Linux 内核是怎么算的呢?
代码路径: https://elixir.bootlin.com/linux/v5.0/source/net/ipv4/tcp_cong.c#L407
/* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w),
* for every packet that was ACKed.
*/
// 我们上面看到了 tcp_cong_avoid_ai 函数的调用时机和入参:
// tcp_cong_avoid_ai(tp, tp->snd_cwnd, acked);
// w 实际就是当前的窗口大小,acked 是累积到当前新的确认的字节数
void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w, u32 acked)
{
/* If credits accumulated at a higher w, apply them gently now. */
// snd_cwnd_cnt 是指已确认字节数(存量)
// 这里意思是,如果 snd_cwnd_cnt 超过一个窗口,则把 snd_cwnd_cnt 重置为 0
// 然后窗口 snd_cwnd + 1
if (tp->snd_cwnd_cnt >= w) {
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd++;
}
// 这里把新的累积确认 acked 加到 snd_cwnd_cnt上
tp->snd_cwnd_cnt += acked;
// 如果加完之后,大于等于窗口大小,则执行拥塞避免算法
if (tp->snd_cwnd_cnt >= w) {
u32 delta = tp->snd_cwnd_cnt / w; // 累积确认/窗口大小 = 已经确认了多少个窗口,注意这里是四舍五入的
tp->snd_cwnd_cnt -= delta * w; // snd_cwnd_cnt = snd_cwnd_cnt - delta * w,实际上就是说可能不是整数个窗口,
// 那我得把剩下的那部分留在 snd_cwnd_cnt 里下次用于计算窗口
tp->snd_cwnd += delta; // 窗口增加 delta 个
}
// 窗口大小不超过最大窗口
tp->snd_cwnd = min(tp->snd_cwnd, tp->snd_cwnd_clamp);
}我们看到代码可以得出,拥塞避免阶段每发送 snd_cwnd 窗口大小个字节,并且收到全部 ACK 后,才能增长 1 字节!增长及其的缓慢!
这个和上面的理论部分,每经过 1 个 RTT(cnwd),cwnd 增长一个 MSS,似乎冲突?
原因在于理论使用的是 窗口大小,单位是 MSS,响应的是接收到的 ACK 包数量
而实际上 cwnd 单位是字节,而不关注 ACK 的数量,使用的是 ACK 的字节数
这也是 TCP 拥塞控制中 ABC 问题,RFC3465 单独有讨论这个问题: TCP Congestion Control with Appropriate Byte Counting (ABC)
当然啦,我们面试考试什么的,还是按照理论的来~ 感兴趣的同学可以多看看实际内核中的实现~
3. 发生拥塞时间处理方法
这种拥塞避免的线性增长什么时候会结束呢?当出现数据包丢失,也就是 RTO 超时的时候,TCP 认为网络可能出现了拥塞,于是重传超时的数据包,同时:
- 更新 ssthresh 为当前 cwnd 一般,即 sshthresh = cwnd/2
- 同时将 cwnd 更新为 1
- 进入慢启动过程
可以看到,当 TCP 发生了 RTO 超时重传的时候,cwnd 就被打回了原型,重新从慢启动开始探测。
显然这个拥塞处理太粗暴了,毕竟偶尔丢个包也不一定是网络拥塞了,完全犯不着 会导致网络传输速度剧烈抖动!

4. 快重传(Fast Retransmit)和快恢复(Fast Recovery)
快重传
但是前面我们提到过丢包事件也能由三个冗余 ACK 事件触发,TCP 认为这种“丢包事件”,相比于 RTO 超时指示的丢包,反应应该不那么剧烈。
这种情况下就是触发快速重传,发送方的行为:
- 收到3个连续重复ACK后立即重传对应报文段
- 不必等到RTO超时,可以更快响应丢包情况
接收方行为:
- 收到数据立即发送ACK确认,不能等待发送数据进行捎带确认
- 对失序数据也要发送重复ACK,而不是等待数据恢复
如图所示:

对于触发快重传场景,早期版本的 TCP Tahoe 算法的实现和 RTO 超时一样:sshthresh = cwnd/2,cwnd=1
由于本身还有一个包重传占用了 cwnd,所以这段时间几乎不能发送新数据。
而后面 TCP Reno(rfc5681) 的处理则会温和很多:
- cwnd 更新为原来一半,cwnd = cwnd /2
- ssthresh 更新为最新的 cwnd ,ssthresh = cwnd
- 然后进入快速恢复阶段
快速恢复
快速恢复算法(Fast Recovery)是 TCP Reno 中用来处理丢包时的一种机制,它通过减少数据包丢失后对窗口大小的调整,避免了像传统的超时重传(RTO)那样的剧烈退避。
引入了快速恢复算法,是为了在恢复丢失数据包期间,还能发送新的数据包,尽量减少丢包期间的网络带宽的浪费,这就是快速恢复名称的由来。
在执行快速恢复算法前,cwnd 和 ssthresh(慢启动阈值)会进行更新(上面已经说了):
- cwnd = cwnd / 2
这表示将当前的拥塞窗口大小减半,反映出网络负载的减少。 - ssthresh = cwnd
设置新的慢启动阈值为当前的窗口大小。
快速恢复算法过程:
- cwnd = ssthresh + 3 * MSS
设置当前的 cwnd 为 ssthresh 加上 3个最大报文段(MSS) 的大小。这个值反映了网络中已经确认接收的 3 个数据包。通过增加 3 * MSS,可以让窗口继续前进,确保可以发送更多的数据。 - 重传丢失的数据包
- 如果继续接收到重复的 ACKs,如果接收到 更多的重复 ACKs,意味着丢失的数据包还没有恢复,TCP 会继续增加 cwnd,即 cwnd = cwnd + 1。每收到一个重复 ACK,就将 cwnd 增加 1
- 如果接收到一个 新的 ACK,即表示丢失的数据包已经恢复并成功接收,此时:
- cwnd = ssthresh,恢复到之前设定的慢启动阈值。
- 随后进入 拥塞避免阶段(Congestion Avoidance),并按正常的拥塞避免算法调整窗口大小。
- 另外,如果在快速恢复期间发生超时重传,则 ssthresh 置为当前 cwnd 的一半,cwnd = 1,重新进入慢启动阶段(意思是,这种情况咱也没法帮你快速恢复,还是老老实实打回原型,重来)
这里会有比较奇怪的地方,为什么快速恢复阶段接收到重复的 ACK,cwnd 需要 + 1 呢?
这里就需要回顾一下滑动窗口的特点了,对于重复 ACK,发送方的 SND.UNA 是不会向右移动的,因为它指向的是已经被确认的最后一个字节:

另外一个角度,收到重复 ACK,说明接收方又收到了新的数据,但由于老的那个包丢失了,它会不断发送相同的 ACK 来通知发送端丢失的包。
收到多个重复的 ACK 说明其它数据包准时到了,网络并不拥塞,只是偶然丢了一个包,所以不能影响我们正常的发送新的数据,但是此时 SND.UNA 无法右移,为了增大可用窗口,就只能扩大整个发送窗口 SND.WND 了!!!!
核心思想就是: 在不影响现有新数据的发送速度的情况,尽量把老的重传回去
还有,为什么在收到新的 ACK 之后, cwnd 需要调整回 ssthresh 呢?难道不能就在当前 cwnd 的基础上执行拥塞避免算法吗?
上面说了,窗口的扩大是因为:窗口被老的那个丢包的占着了,所以我需要临时扩大窗口,但是解决了那个老的丢包(收到新的 ACK)之后,那么就应该还原。
(PS:实际上不还原,应该也可以? 搞不懂,,感觉这些就是经验做法,大家领略到大概的思想即可,只要不是考研,不会具体让你计算某个时刻的 cwnd 的~)
5. TCP New Reno
RFC6582: The NewReno Modification to TCP's Fast Recovery Algorithm
6. TCP BIC
7. TCP Cubic
具体例子
让我们通过一个具体的例子来说明整个过程:
初始状态:
- cwnd = 1 MSS
- ssthresh = 16 MSS
慢启动阶段:
- 第1个RTT后:cwnd = 2 MSS
- 第2个RTT后:cwnd = 4 MSS
- 第3个RTT后:cwnd = 8 MSS
- 第4个RTT后:cwnd = 16 MSS = ssthresh
进入拥塞避免阶段:
- 第5个RTT后:cwnd = 17 MSS
- 第6个RTT后:cwnd = 18 MSS
- 第7个RTT后:cwnd = 19 MSS
假设此时检测到丢包(收到3个重复ACK):
- 新的ssthresh = cwnd/2 = 9 MSS
- cwnd = 9 MSS
- 进入拥塞避免阶段继续传输
总结
TCP的拥塞控制机制通过:
- 慢启动快速探测网络容量
- 拥塞避免谨慎提升速率
- 快重传和快恢复及时应对丢包
这些算法共同作用,既保证了网络的高效利用,又避免了网络拥塞。就像一个好司机,根据道路状况灵活调整车速,在确保安全的同时提高行驶效率。