2025年Gemini 3发布!Google Gemini 3 Pro/Ultra功能解析、入口与国内注册使用教程
Gemini 3发布!Google Gemini 3 Pro/Ultra功能解析、入口与国内注册使用教程
2025年11月19日,谷歌正式发布Gemini 3,这不仅是模型能力的迭代,更是一场关于AI交互形态的革命。
在OpenAI和Anthropic激烈竞争的背景下,Gemini 3的亮相标志着谷歌首次将"顶级模型能力"与"全球最大入口产品"实现同步结合。从发布第一天起,Gemini 3就部署在Google搜索的AI模式、Gemini App及开发者平台,展现出前所未有的生态整合速度。
在哪里可以用 Gemini 3?
Gemini 3 Pro你在AI Studio里就能用到。
网址:https://aistudio.google.com/
Google Gemini网页版也已经上线。
如果你的谷歌账号被限制地区访问不了,可以去 国内最专业的AI 代充平台 买一个 gemini pro 的账号~
三大核心突破:上下文、多模态与智能体
百万Token上下文窗口:重新定义长文本处理
Gemini 3最引人注目的技术参数是1,048,576 tokens(约78万字)的超大上下文窗口,相当于10本书的容量。相比之下,Claude 3.5 Sonnet为200,000 tokens,GPT-4o为128,000 tokens。实测显示,当文档超过模型窗口时,分段处理会导致跨段落推理准确率下降15-25%。在法律合同审核、学术文献综述等场景中,Gemini 3的超大窗口展现出不可替代的优势。
这一突破不仅限于文本任务,更显著增强了多模态推理和智能体能力。模型可同时分析数小时视频及其字幕,实现深度文本-视频信息融合;在自动化智能体系统中,能记住所有任务步骤、中间结果和环境状态。
全球顶尖的多模态推理
Gemini 3保留了跨模态信息综合能力,能无缝处理文本、图像、视频、音频和代码。无论是破译不同语言的手写食谱、分析匹克球比赛录像提供训练计划,还是从学术论文和长视频讲座生成交互式学习卡片,模型展现出对真实世界复杂信息的深度理解能力。
登顶Vending-Bench 2:智能体能力突破
在测试长期规划能力的Vending-Bench 2排行榜上,Gemini 3位居榜首。它能在整整一年的模拟运营中保持一致的工具使用和决策能力,不偏离任务轨道。这标志着AI首次具备真正可靠的"代理"能力,可自主规划并执行多步骤复杂任务,如整理Gmail收件箱、预订旅行、处理工作流等。
生成式UI:从"聊天"到"生成世界"
Gemini 3最大的颠覆在于"生成式界面"(Generative UI)。传统AI交互是静态的文本问答,而Gemini 3能根据提示即时"编码"生成定制的可视化交互界面。这不仅是功能升级,更是交互范式的根本转变。
谷歌在Gemini App中率先推出两项实验功能:
- 视觉版面布局:生成沉浸式、杂志风格的视图,如规划罗马三天行程时可获得可探索的视觉化行程表
- 动态视图(Dynamic View):运用代理式编程能力,实时设计并编写完全符合需求的定制化界面。例如询问梵高画作时,会收到一个可点击、滑动的互动式界面
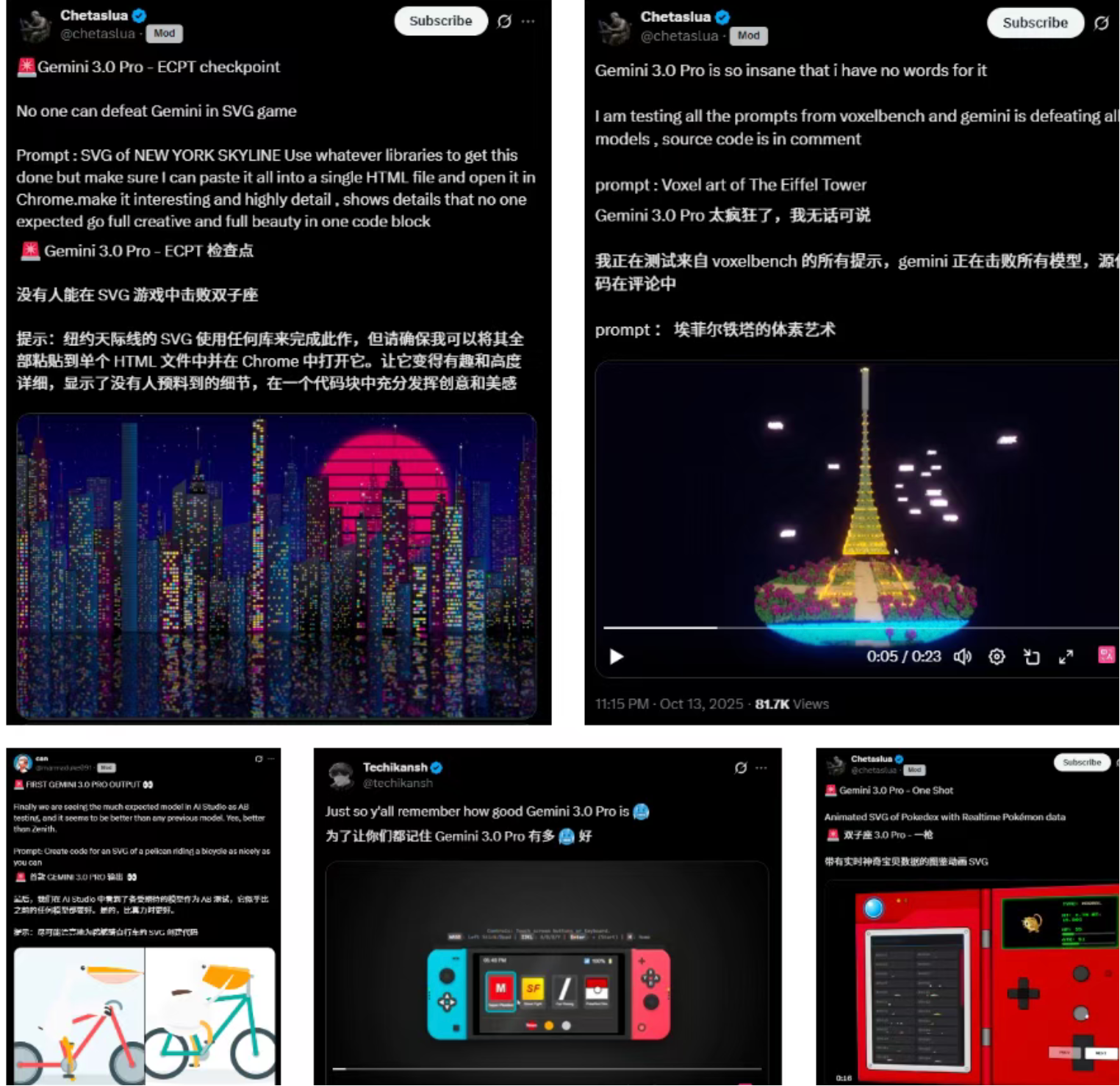
正如谷歌团队所言:"过去ChatGPT式的一问一答是上个时代的做法,现在Gemini要直接给你全模态的可交互结果。" 用户甚至可以用一个词触发一个可交互的3D模拟器,并继续用自然语言开发成完整项目。
性能数据:全面领先
在实际性能对比中,Gemini 3.0 Pro展现出显著优势:
| 测试场景 | Gemini 3.0 Pro | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|
| 短文本生成(500 tokens) | 1.8秒 | 2.1秒 | 2.4秒 |
| 长文本生成(5000 tokens) | 14.2秒 | 16.8秒 | 18.5秒 |
| 单图像分析 | 2.3秒 | 2.6秒 | 3.1秒 |
| 多图像分析(4张) | 5.7秒 | 6.9秒 | 8.2秒 |
| 代码生成(200行) | 8.1秒 | 9.3秒 | 10.2秒 |
Gemini 3比GPT-4o快14-20%,比Claude 3.5快25-32%。在高并发场景下,这种速度优势对智能客服、代码补全等实时应用至关重要。并发限制方面,免费版60 QPM,付费版高达10,000 QPM,远超竞争对手。

生态整合:从模型到入口的闪电战
Gemini 3的战略意义在于谷歌首次将"模型—产品—入口—分发—生态"连成一线。传统上,大模型从训练到进入搜索、Android或Workspace需要跨越多个链路:训练→API→应用→终端整合→全球推送。而Gemini 3的路径几乎是同步发生。
发布当天即上线搜索AI模式,这是谷歌从未有过的节奏。这表明谷歌认为该模型已训练到足够稳定,可直接融入主营业务,无需担心技术反噬。这种"模型能力"与"全球入口"的即时结合,让谷歌重新获得快速推开用户端体验的能力。
配合发布,谷歌还推出:
- Google Antigravity开发平台:让开发者像"指挥官"管理多个AI代理在编辑器、浏览器和终端自主工作
- Google AI Ultra订阅:提供Gemini Agent等高级功能,Plus、Pro和Ultra用户享有更高使用额度
- 台湾大学生免费试用:扩展Google AI Pro一年免费试用至全台湾大学生,至12月9日截止
战略意义:谷歌重回牌桌中央
过去一年,业界普遍认为谷歌在应用层落后,执行能力和产品节奏被竞争者拉开差距。但Gemini 3的亮相让谷歌的结构性优势实现完整对齐。
当TPU、模型、安卓、搜索、Chrome、Workspace被拉到统一节奏,复杂性开始反向成为优势。Gemini 3在这个技术栈中获得乘数效应:TPU提供训练与推送能力、搜索承担流量入口、Android与Chrome撑起交互层、Workspace负责执行任务、Antigravity解决开发者协作。
相比之下,大多数竞争者只能在链条的一部分取得突破,难以在"入口—交互—执行—生态"四个层面同时推进。这重新明确了一个判断:谷歌依然是少数能把顶级模型能力直接压到全球主流应用体系中的巨头。
从"Vibe Coding"到现实应用
谷歌团队在训练过程中经历了多个"Aha moments"。最直观的体验是"氛围编码"(vibe coding)——用非常模糊和简短的提示,模型就能从零生成各种游戏,构建3D画面并直接可玩。
实际应用场景包括:
- 教育:上传作业照片获得额外指导,整理错过的讲座笔记
- 购物:从500亿条商品信息的Google Shopping Graph直接导入产品列表、比较表和价格
- 开发:用自然语言描述想法即可转化为功能丰富的应用或精美界面
- 研究:分析数小时视频讲座、复杂学术论文
挑战与未来
尽管进步显著,Gemini 3仍面临挑战。谷歌表示模型将表现出更少的"逢迎"现象,对提示词注入抵抗力更强,并改进了对网络攻击滥用的防护。但生成式UI的稳定性、跨平台一致性(目前移动端Canvas质量优于网页版),以及如何平衡开放性与安全性,都是需要持续优化的方向。
未来几周,谷歌将通过Gemini 3强化搜索中的自动模型选择功能,智慧地将最具挑战性的问题导给这个最先进模型。同时,Gemini Agent功能将扩展到更多谷歌产品。
END
Gemini 3不仅是参数和性能的胜利,更是AI交互逻辑的重构。当模型开始"生成"界面而非仅仅"生成"文字,当搜索从提供链接变为提供可交互应用,当复杂任务的自主执行成为可能,我们正见证人机协作的新纪元。
谷歌用Gemini 3证明:在AI竞争中,单一模型优势不足以制胜,真正的护城河是模型、入口、生态与分发体系的完整闭环。这场竞赛的牌桌形状,确实从此刻开始发生了变化。