系统设计(面试篇)
在这篇文章中,我说要更新一个「Interview-oriented system design」系列。
目的就是让大家知道系统设计都在设计个啥,怎么用套路去解决面试中的问题。
建议大家也关注下这个公众号,我会不定期更新在两个公众号。
不过目前「Java编程指北」的关注还不多,发的文章看的人也不多,暂时这篇就更新在「编程指北」了。
一、系统设计是什么?
一说到系统设计,可能大家脑子里就冒出了高并发、微服务、负载均衡、分布式、集群、CAP、一致性哈希、......这样高大上词语。
我觉得系统设计就是如何把资源最优化配置,简单来说就是你需要设计计算、存储各个模块,并且是在一定的限制条件下。
这个过程中,你需要设计系统的架构、模块、接口和以及数据存储方式。
系统设计中最核心的是什么?
我个人认为是设计数据存储和访问方式。
为什么?
「数据是架构的核心」,互联网公司的主流业务,本质上就是一个数据处理系统:
应用层的业务逻辑操作着底层复杂的数据系统
咱们后台同学平常自嘲是 CRUD Boy 也不是没有道理的,本来就是用代码对着数据存储层一顿狂操作。
平时研发流程,也是先进行领域模型设计和数据模型设计,然后才是定义接口,最后才开发。
所以,充分理解数据系统的运作和设计非常必要, 我们常见的数据处理方式包括关系型数据库、NoSQL、大数据存储、流式数据存储等,各有优缺点和适应的场景。
数据存储使用不同的系统,那么对应的业务逻辑实现也是有很大区别的。
比如订单系统,这类系统一般都需要一个全局的 ID 生成器,如果订单采用 MySQL 存储的话,我们就需要考虑 ID 生成器的策略是随机还是递增的。
因为如果是随机生成,那么插入MySQL Innodb 表的时候,底层的 B+ 树索引也许会发生页分裂等问题,影响插入性能。
像电商如果遇到大促,短时间生成大量订单,写入就会成为瓶颈?
现在典型的数据模型有:
关系型:
基于关系模型,主要面向OLTP(on-line transaction processing在线事务处理),在线指的是比如银行转账、商品下单这类实时流程操作。
要求严格的 ACID,支持事务。
典型的如互联网公司最爱的MySQL、财大气粗的三桶油银行最爱的 Oracle等都是关系型数据系统的代表。
NoSQL(Not Only SQL):
这类系统以放宽 ACID 原则为代价,NoSQL采取的是最终一致性原则,而不是像关系型数据库那样地严格遵守着ACID的原则,这意味着如果在特定时间段内没有特定数据项的更新,则最终对其所有的访问都将返回最后更新的值。
这就是这样的系统通常被描述为提供基本保证的原因(基本可用,软状态,最终一致性) — 而不是ACID。
NoSQL 的范围很广,理论上不是基于关系模型的数据存储系统都可以叫做 NoSQL,比如列存储 Hbase,图存储 Neo4J、对象存储、KV存储 Redis、Memcache等。
(关于数据存储这方面推荐去看看 《ddia》 这本书,比较详细的论述了各种数据存储模型。
正是由于 MySQL 这类传统关系型数据库在面对互联网公司海量的用户请求时有各种各样的瓶颈,比如:
- 高并发读写需求
网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。 - 海量数据的高效率读写
网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
而常见的解决思路也是垂直拆分或者水平拆分,用各种中间件去做 Sharding,即 单机RDBMS + 中间件,但是在中间件层是比较难解决分布式事务、高可用等问题的。
并且 Sharding 本身也是会带来一堆问题的。
所以对于那种对 ACID 要求不是很严的场景,是有不少 NoSQL 系统可以取代的,比如 面向高性能并发读写的 key-value数据库:Redis,Tokyo 等
面向海量数据访问的面向文档型数据库:MongoDB
但是 NoSQL 还是不能完全取代 RDBMS,所以现在又有 NewSQL 出来了。
NewSQL 的设计架构基本是下面这些:
- 基于多副本实现高可用和容灾
- 分布式查询
- 数据 Sharding 机制
- 通过2PC,Paxos/Raft 等协议实现数据一致
Google 算是这方面的鼻祖,后来很多的 NewSQL 数据库基本都是按照 Spanner/F1 论文去实现的。
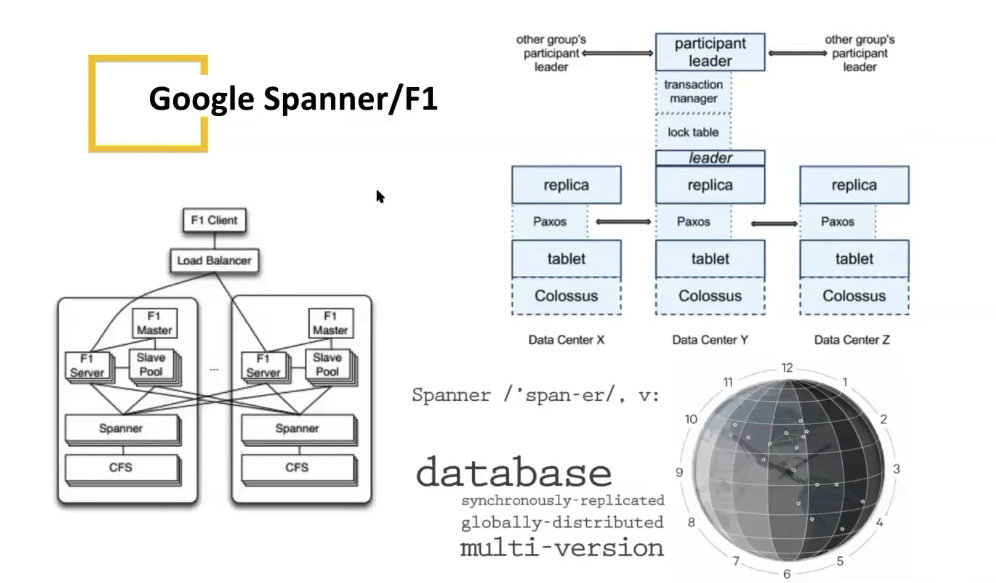
学习的话,可以看国内 PingCAP 开源的 TIDB: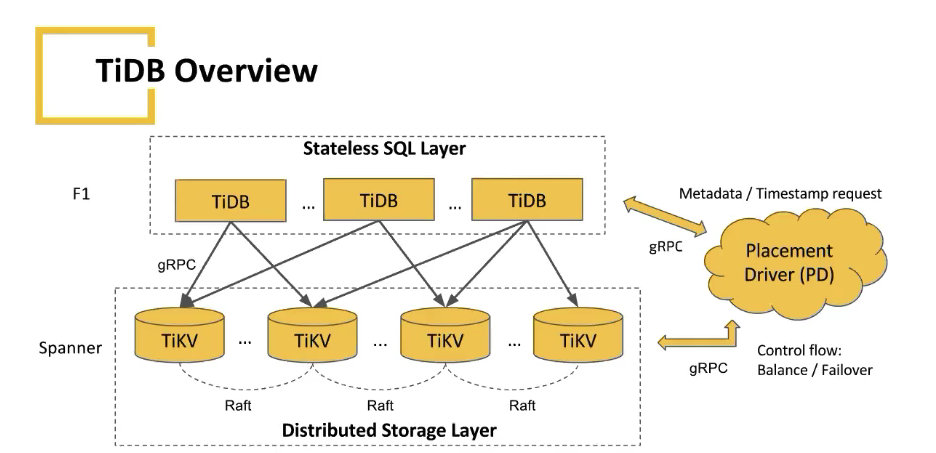
基本上就是底层使用 TiKV:
百度:TiKV 是一个开源的分布式事务 Key-Value 数据库,专注为下一代数据库提供可靠、高质量、实用的存储架构。最初由 PingCAP 团队在 2016 年 1 月作为 TiDB 的底层存储引擎设计并开发。
大家感兴趣可以去 TIDB 官网看看它的整体架构介绍:
https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
感觉跑偏了,说到了分布式数据库去了,这方面我也只是了解个大体,还是回到我们的系统设计上来。
二、系统设计的武器库
这一节就是简单介绍下系统设计的一些”武器库“,其实说白了就是,就是你要做去分布式、高可用、高性能......,都有哪些组件、方法论、设计套路可以选择。
为什么要先列出这些武器库呢,因为大家都知道系统设计实际上是基于各种场景和给定资源下做 Trade-off,所以首先得知道都有哪些方案,从哪些角度去 Trade-off。
在这里给大家总结了一个列表,大家可以对照的去了解这个技术点,基本上也是后端开发必备的一些分析系统和设计系统的技术栈:
2.1 估算:网络、磁盘、IO等
- CPU/Memory/Network Bandwidth
- TCP/IP Model
- TCP vs UDP
- DNS lookup
- HTTPS vs TLS
- Random vs sequential read/write on disks
- Datacenters / Racks/ Hosts
- IPv4 vs IPv6
- http vs http2 vs web sockets
首先,第一块是硬件和资源的估算,这里的硬件和资源比较广义,包含了存储、运算力、网络等。
像 TCP/IP Model、TCP、UDP 这些都是必需要知道的东西,这样才能选择适合的网络协议栈。
比如音视频、直播、游戏大多都是用的 UDP 来包一层可靠传输,这样可以达到更高的网络通信效率,因为 TCP 本身的慢启动、避让机制是对于整个网络最优的,有些策略对于我们应用却是不必要的,我们可以”自私“、”贪心“一点。
了解磁盘、文件、数据库在顺序写和随机写上的速度差别,也可以给我上层应用实现的时候,
2.2 锁、同步
- Multithreading, Concurrency, locks, Synchronization.
- Optimistic vs pessimist locking.
应用系统最终都是处理数据的,如何保证数据被正确的处理,不会出现并发问题,这就是并发控制需要考虑的问题。
两个典型的思想,乐观和悲观,对应于:
- 悲观锁(Pessimistic Locking)
- 乐观锁(Optimistic Locking)
思想非常好理解, 悲观锁假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
也就是说,悲观锁要求对数据的修改,都必须先抢到锁。
悲观锁主要用于资源并发写很多的情况。
而乐观锁假定不会发生并发冲突,只在提交操作时检查是否违反数据完整性。
常见的操作就是利用版本号 version,做一个 CAS 操作。
比如对于 SQL 的话就是这样:
UPDATE orders set status = "发货", version = version + 1
WHERE version = 2 and order_id = xxxx;通俗点理解就是,我拿到数据的时候版本是 version,然后我在内存中做了一些操作,更新数据库的时候,那么必须满足更新时的版本号也是 version,如果版本号和我持有的不一样,那么就是中途有其它人修改了。
那么我这次更新就失败,应该重新从数据库取出最新数据进行操作。
2.3 分布式、事务相关理论
- CAP Theorem
- ACID and BASE properties
- Strong vs Eventual Consistency
这块就是分布式基础理论、分布式事务,包括 CAP 理论、事务的 ACID等特性。
还有我们系统的数据是要求强一致性还是最终一致性呢?
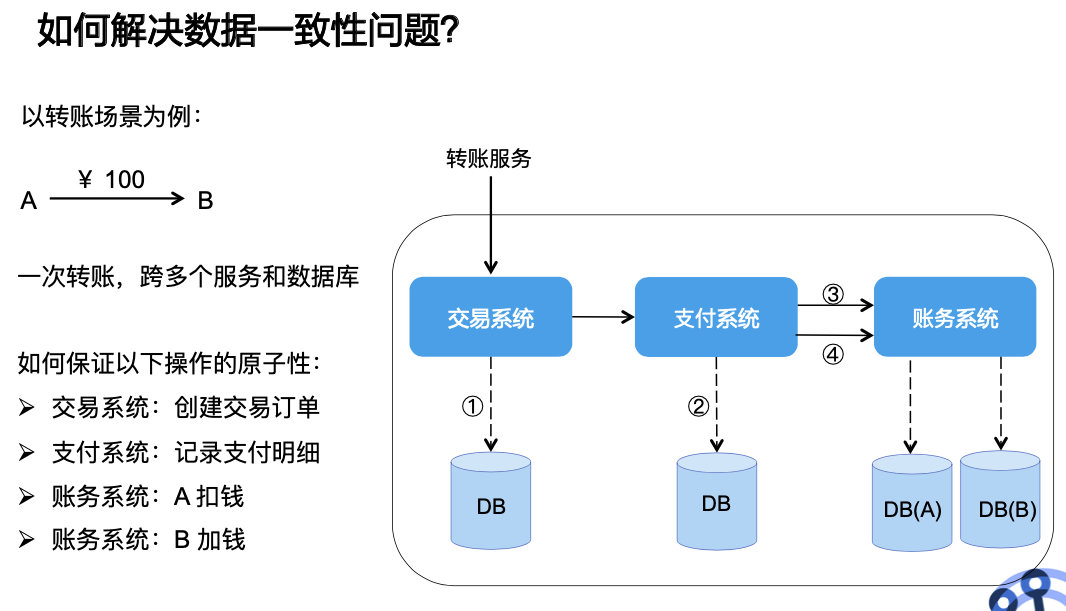
数据一致性,简单来理解,就是我们的业务一般都会涉及到多个系统,比如订单、劵系统、账务、支付等。
那么一个操作跨系统的时候,比如转账、下单支付,如何保证一次业务操作跨系统实现原子性,也就是要么都成功,要么都不成功,不能出现部分成功这种,如下图:
数据强一致性常见的解决方案又有 2PC,或者改进版本 3PC、TCC 等,这些分布式事务解决方案基本就是现成的,都是前人总结好的,我们只需要去学习、理解、应用就好了。
2.4 数据冗余和拆分
Vertical and Horizontal Scaling
Partitioning or Sharding data
Consistent Hashing
这三点基本都在做一个事,就是数据的 Shading。
当我们的数据库单机无法承受高强度的i/o时,就考虑利用 Sharding 来把这种读写压力分散到各个主机上去。
而 Sharing 又分为水平拆分和垂直拆分,水平拆分就是将一个库,分散为库1、库2:
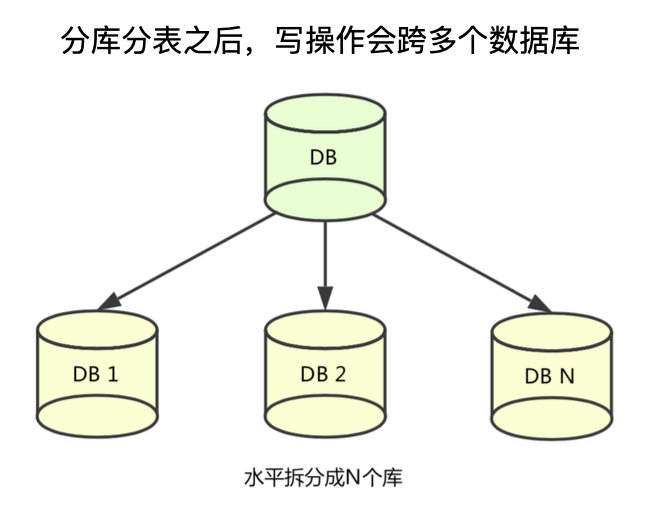
一般拆分的依据就是根据一个 Sharding key,比如 用户 ID,最简单的取余即可判断某个用户应该去哪个库:
if ID % 3 == 0:
// database 1
elif ID % 3 == 1:
// database 2
else:
// database 3但是这样的缺点就是,扩容或者宕机的时候迁移数据很麻烦,比如由于业务发展,我们需要增加两台机器作为 DB4和 DB 5,那么这时候我们就应该对 5 取余。
那么之前对 3 做 Sharding 就会全部失效,所以我们需要对 DB1、DB2、DB3的所有数据进行重新 Sharding 到五台 DB。
这样的操作显然不行,扩容和宕机时必须停服进行数据迁移,那有没有一种更好的办法,让添加或者删除 Sharding 节点对整个分片系统的数据迁移量降低呢?
那么就引入了一致性哈希,一致性哈希主要就是解决宕机和扩容的问题。
具体什么是一致性哈希,可以去网上看下博客,也很好理解。
2.5 高性能
- Caching
- Load Balancers
- CDN’s
缓存应该是后台最简单、最直接的提高性能的方式之一了。
在计算机中,缓存是存储数据的硬件或软件组件,以便可以更快地满足将来对该数据的请求。
存储在缓存中的数据可能是之前计算结果,也可能是存储在其他位置的数据副本。
缓存本质来说是使用空间换时间的思想,它在计算机世界中无处不在, 比如 CPU 就自带 L1、L2、L3 Cache,这个一般应用开发可能关注较少。但是在一些实时系统、大规模计算模拟、图像处理等追求极致性能的领域,就特别注重编写缓存友好的代码。
缓存之所以能够大幅提高系统的性能,关键在于数据的访问具有局部性,也就是二八定律:「百分之八十的数据访问是集中在 20% 的数据上」。
这部分数据也被叫做热点数据。
缓存一般使用内存作为存储,内存读写速度快于磁盘,但容量有限,十分宝贵,不可能将所有数据都缓存起来。
如果应用访问数据没有热点,不遵循二八定律,即大部分数据访问并没有集中在小部分数据上,那么缓存就没有意义,因为大部分数据还没有被再次访问就已经被挤出缓存了。每次访问都会回源到数据库查询,那么反而会降低数据访问效率。
2.6 数据模型选型
- Relational vs No SQL DB
2.7 设计模式
- Design Pattern and Object Oriented design
2.8 其它
- Publisher-Subscriber
- Map reduce
- Long-Polling vs Websocket
三、总结
这里只是简单给大家列举了一些技术点,大家可以对照着去了解这些技术是什么?适用哪些场景?各自的优劣,我就不一一的介绍了。
大家如果要系统学习系统设计的话,可以去看下这门课,不过是英文的:
《Grokking the System Design Interview》
大家记得帮我一键三连噢,在看点一点,助理更新起来会更有动力的~